
Data Annotation Platform
Data Annotation Platform
February 2021 — December 2021
Project worked in close collaboration with the CPO of a Fortune 500 company, with the goal of redesigning and expanding their data annotation tool, used by over 5,000 employees around the world. This was a high-profile project for both my company and the client, and required extensive user research and ideation to fulfill the large scope and complex requirements.
Participation
Interaction design
Product infrastructure
User research
Acceptance criteria
Dev support
Client communications
UX Team



A powerful new tool
Bluefish is an American Fortune 500 company that facilitates the creation and management of digital information. With this project, we were tasked with redesigning and expanding their internal work tool used to annotate large quantities of data intended for artificial intelligence training. The project later evolved into an SaaS product marketed towards a wider audience.
Here is a promotional video showcasing the different annotation tools.
Bluefish is an American Fortune 500 company that facilitates the creation and management of digital information. With this project, we were tasked with redesigning and expanding their internal software used to annotate large quantities of data intended for artificial intelligence training. The project later evolved into an SaaS product marketed towards a wider audience.
Here is a promotional video showcasing the different annotation tools.
What is data annotation?
The platform is used to parse, annotate, and export four types of data: spreadsheets, documents, text, and images. Each piece of data is classified using one of the company's taxonomy lists, for example classifying "New York" as a "City".
Internally, this tool is used by over 5,000 employees from all parts of the world and of all backgrounds, as a simple, remote work position. Employees are assigned batches of data, which they need to classify one by one before sending it for export.
A powerful new tool
Bluefish is an American Fortune 500 company that facilitates the creation and management of digital information. With this project, we were tasked with redesigning and expanding their internal work tool used to annotate large quantities of data intended for artificial intelligence training. The project later evolved into an SaaS product marketed towards a wider audience.
Here is a promotional video showcasing the different annotation tools.
What is data annotation?
The platform is used to parse, annotate, and export four types of data: spreadsheets, documents, text, and images. Each piece of data is classified using one of the company's taxonomy lists, for example classifying "New York" as a "City".
Internally, this tool is used by over 5,000 employees from all parts of the world and of all backgrounds, as a simple, remote work position. Employees are assigned batches of data, which they need to classify one by one before sending it for export.
Creating the workbenches
The most important part of the platform are the annotation workbenches, where Annotators work through classifying their assigned data batches. There are four workbenches, each one tailor-made for each type of data, taking into account how to best visualize and classify them.
Spreadsheets Documents Images Text

To begin working through the monumental amount of requirements, we first designed the layout that would be used across all workbench types. The main part is the toolbar, where we placed the different features into tabs, including a hierarchical category list, annotator comments, project guidelines, and a fully customizable hotkey menu.
Workbench toolbar

Data categories

Batch comments

Project guidelines

Hotkeys
Project guidelines
Hotkeys
Creating the workbenches
The most important part of the platform are the annotation workbenches, where Annotators work through classifying their assigned data batches. There are four workbenches, each one tailor-made for each type of data, taking into account how to best visualize and classify them.
Spreadsheets Documents Images Text
To begin working through the monumental amount of requirements, we first designed the layout that would be used across all workbench types. The main part is the toolbar, where we placed the different features into tabs, including a hierarchical category list, annotator comments, project guidelines, and a fully customizable hotkey menu.
Workbench toolbar
Data categories
Batch comments
Project guidelines
Hotkeys
Project guidelines
Hotkeys
Record Classification
The first workbench was Record Classification, used to annotate data in CSV and spreadsheet formats, with each row being one piece of data. This was the moment when we realized how complex this project would be, as the list of requirements for this flow was unlike anything I had worked through before.

We spent a long time working the design at a purely UX level, collaborating closely with the client and users alike to validate that the tool was fulfilling the many requirements properly before moving on to creating the UI.

Project name
Batch metadata
Comments
Project
guidelines
Frequent categories
Data
categories
Hotkeys
Dynamic pagination
Fixed columns
Secondary columns
Selected
categories
Overflow
indicator
Previous / Next columns
Project name
Batch metadata
Comments
Project
guidelines
Frequent categories
Data
categories
Hotkeys
Dynamic pagination
Fixed columns
Secondary columns
Selected
categories
Overflow
indicator
Previous / Next columns
The most challenging part was finding a way to include the large and variable amounts of columns that each data batch included, while still highlighting the most important columns used to annotate. These columns had to be fully customizable from one data batch to another.
The most challenging requirement was finding a way to include the large and variable amounts of columns that each data batch included, while still highlighting the most important columns used to annotate. These columns had to be fully customizable from one data batch to another.

Take a look at what the record classification process looks like!
Record Classification
The first workbench was Record Classification, used to annotate data in CSV and spreadsheet formats, with each row being one piece of data. This was the moment when we realized how complex this project would be, as the list of requirements for this flow was unlike anything I had worked through before.
We spent a long time working the design at a purely UX level, collaborating closely with the client and users alike to validate that the tool was fulfilling the many requirements properly before moving on to creating the UI.
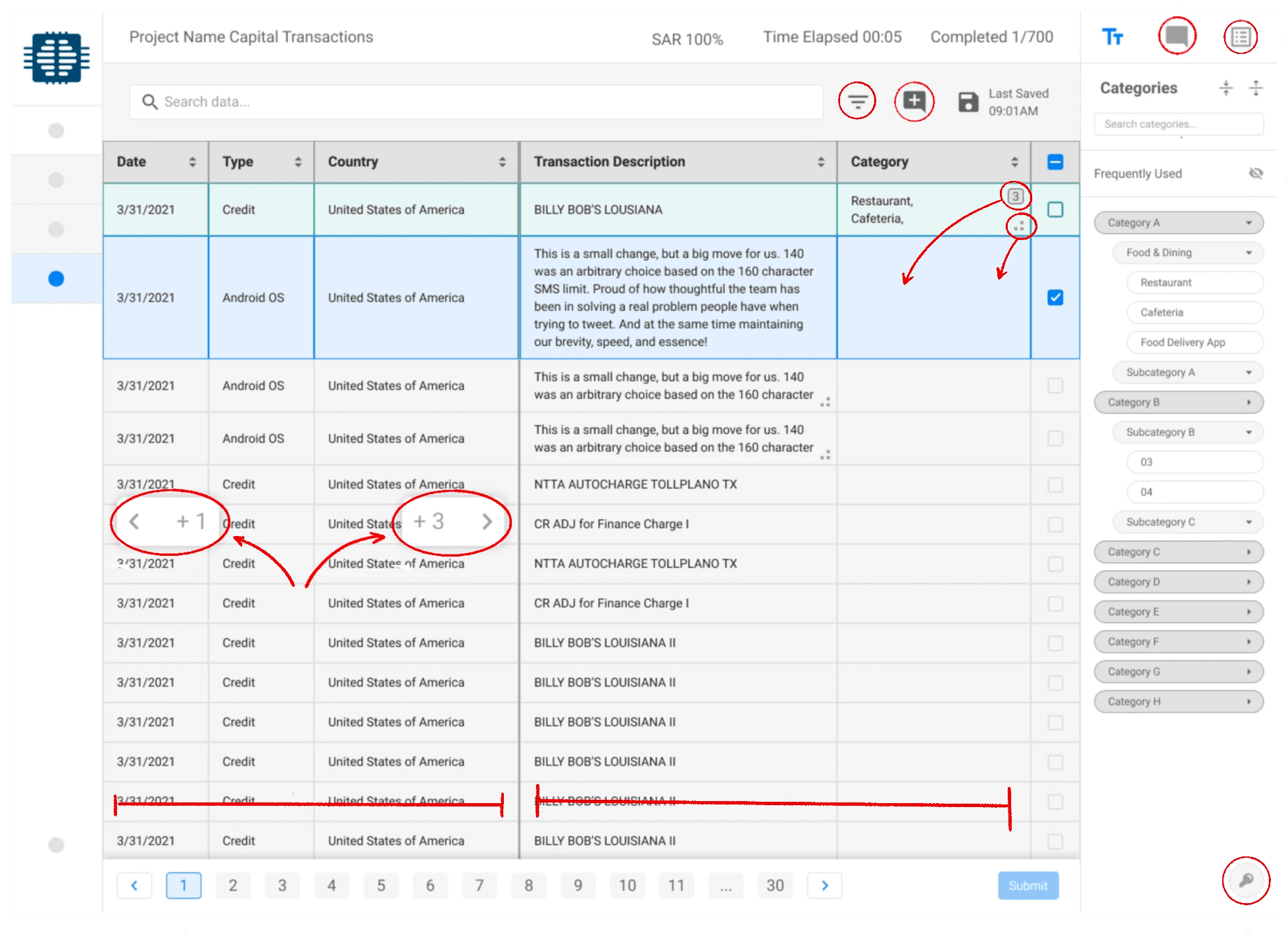
Project name
Batch metadata
Comments
Project
guidelines
Frequent categories
Data
categories
Hotkeys
Dynamic pagination
Fixed columns
Secondary columns
Selected
categories
Overflow
indicator
Previous / Next columns
The most challenging part was finding a way to include the large and variable amounts of columns that each data batch included, while still highlighting the most important columns used to annotate. These columns had to be fully customizable from one data batch to another.
Take a look at what the record classification process looks like!
In Line Classification
In Line Classification
The last workbench I designed for the project was In Line Classification. Here, users annotate text by selecting a word or a phrase and categorizing it to create an entity. Entities could then be further annotated by selecting attributes or creating relationships with other entities in the form of links or groups.
The last workbench I designed for the project was In Line Classification. Here, users annotate text by selecting a word or a phrase and categorizing it to create an entity. Entities could then be further annotated by selecting attributes or creating relationships with other entities in the form of links or groups.

We had to create a new version of the toolbar that accounted for the specific requirements of this data type. Categories were color-coded so that entities could be easily distinguishable within the text, and additional properties such as attributes, links, and groups can be managed within the toolbar after selecting an entity.
We had to create a new version of the toolbar that accounted for the specific requirements of this data type. Categories were color-coded so that entities could be easily distinguishable within the text, and additional properties such as attributes, links, and groups can be managed within the toolbar after selecting an entity.
In Line categories
Entity properties
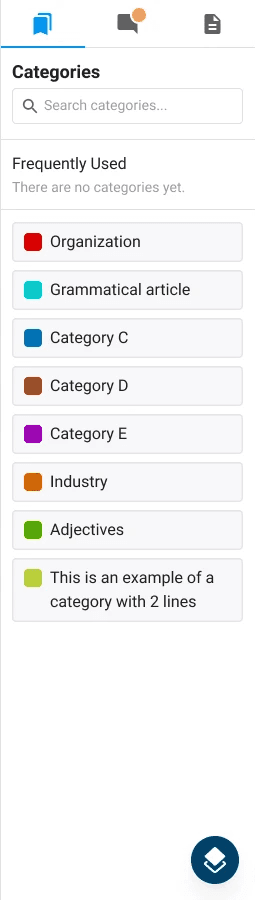

Data categories with color coding
Data categories with color coding
Data categories
with color coding
Hotkeys
Hotkeys
Hotkeys
Frequent categories
Frequent categories
Frequent
categories
In Line categories
Entity properties
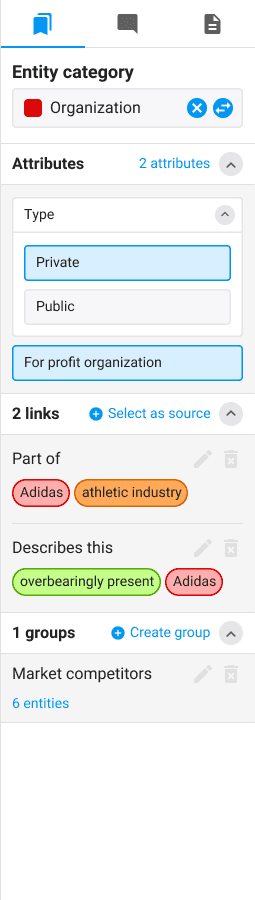
Hotkeys
Entity groups
Entity groups
Entity groups
Selected category for the entity
Selected category for the entity
Selected category for the entity
Entity attributes
Entity attributes
Entity attributes
Entity links
Entity links
Entity links
Visualizing entities
Visualizing entities
Since this workbench revolves around entities, we had to create a simple but easily recognizable component to showcase entities within the text.
This component had to account for the different states of entities, such as the ones that were actively selected, had additional properties, included comments, and more. All of this had to be done without breaking the text layout.
Since this workbench revolves around entities, we had to create a simple but easily recognizable component to showcase entities within the text.
This component had to account for the different states of entities, such as the ones that were actively selected, had additional properties, included comments, and more. All of this had to be done without breaking the text layout.
Uncategorized text


Simple entity without properties
Entity with properties

Entity with annotator comment

Entity selected as link source

Uncategorized text
Simple entity without properties
Entity with properties
Entity with annotator comment
Entity selected as link source

Guiding development
Guiding development
To deliver the design to the developers, I had to create a new type of technical specification card that could properly showcase all the different behaviors and properties of these components.
This turned out to be one of the most complex flows my agency has ever worked in and quickly became one of my favorite features to work on from my design career thus far.
To deliver the design to the developers, I had to create a new type of technical specification card that could properly showcase all the different behaviors and properties of these components.
This turned out to be one of the most complex flows my agency has ever worked in and quickly became one of my favorite features to work on from my design career thus far.
Take a look at what the in line classification process looks like!
Take a look at what the in line classification process looks like!

Back to Home
Ensuring data accuracy
The platform also included data arbitration to ensure the quality of the data. Arbitrators are a different type of employee, responsible for validating the annotated data to either confirm or change the categories selected by the Annotators before sending them through for export.
Arbitrator

Annotator 1
Annotator 2
Annotator 3
Arbitrators have their own version of the workbenches, where instead of classifying data, they select between the categories selected by the different Annotators that worked on the batch. Once a batch has been fully annotated and arbitrated, it's finally sent to the Project Manager to export and input into the machine learning system.
Arbitration workbench displaying the different categories selected by Annotators
Categories selected by Annotator are shown as quick-select in the Toolbar.
Categories selected by Annotator are shown as quick-select in the Toolbar.
Displays one column per Annotator, with their selected categories and any comments they leave.
Displays one column per Annotator, with their selected categories and any comments they leave.
Ensuring data accuracy
The platform also included data arbitration to ensure the quality of the data. Arbitrators are a different type of employee, responsible for validating the annotated data to either confirm or change the categories selected by the Annotators before sending them through for export.
Arbitrator
Annotator 1
Annotator 2
Annotator 3
Arbitrators have their own version of the workbenches, where instead of classifying data, they select between the categories selected by the different Annotators that worked on the batch. Once a batch has been fully annotated and arbitrated, it's finally sent to the Project Manager to export and input into the machine learning system.
Arbitration workbench displaying the different categories selected by Annotators
Categories selected by Annotator are shown as quick-select in the Toolbar.
Displays one column per Annotator, with their selected categories and any comments they leave.
Beyond the workbenches
The platform was designed for company-wide use, allowing for multiple projects to be ran concurrently. For this, we included many other sections such as a comprehensive management system used by Project Managers to assign and manage the work done by Annotators and Arbitrators. We also created a Category List Editor, where managers can easily create new taxonomy files without having to input them from .csvs.





Project Main Page
Each project has a dashboard with relevant information about assigned tasks, data management, user tracking, KPIs, and more. While the dashboard is available to all roles, many of the dedicated project features are locked behind role-permissions.

Beyond the workbenches
The platform was designed for company-wide use, allowing for multiple projects to be ran concurrently. For this, we included many other sections such as a comprehensive management system used by Project Managers to assign and manage the work done by Annotators and Arbitrators. We also created a Category List Editor, where managers can easily create new taxonomy files without having to input them from .csvs.
Project Main Page
Each project has a dashboard with relevant information about assigned tasks, data management, user tracking, KPIs, and more. While the dashboard is available to all roles, many of the dedicated project features are locked behind role-permissions.
In closing
In closing
The project ended after a year and the design was handed to the client to finish development. It was launched to the market in 2022 as a SaaS product, and has since been ongoing further development from Bluefish' internal design team.
This product has been a highlight of my career due to the complexity of what we set out to achieve. It was the moment I truly fell in love with digital product design and solidified my interest in designing large-scale and specialized software.
The project ended after a year and the design was handed to the client to finish development. It was launched to the market in 2022 as a SaaS product, and has since been ongoing further development from Bluefish' internal design team.
This product has been a highlight of my career due to the complexity of what we set out to achieve. It was the moment I truly fell in love with digital product design and solidified my interest in designing large-scale and specialized software.





Data Annotation Platform
February 2021 — December 2021
Project worked in close collaboration with the CPO of a Fortune 500 company, with the goal of redesigning and expanding their data annotation tool, used by over 5,000 employees around the world. This was a high-profile project for both my company and the client, and required extensive user research and ideation to fulfill the large scope and complex requirements.
Product design
Desktop/Mobile
Team building
Project management
Development guidance
